
In the rapidly evolving digital payments landscape, the rise of online payment services and card-based payment methods has brought about a pressing concern – the escalation of cybersecurity threats and credit card fraud. Today, users of digital payment services are bombarded with all kinds of social engineering attempts – from phishing emails to malicious software and phone calls, impersonating bank employees or social service workers. Fraudsters are using sophisticated, multi-stage social engineering schemes, which makes them even harder to detect without incorporating machine learning in the processes. We can see this trend from the latest statistics on social engineering.
"98% of all cyber attacks rely on some form of social engineering."
Catherine Reed Tweet
But it’s not only multi-vector attacks that make social engineering so difficult to detect. Social engineering schemes typically target the end users – the least technologically sophisticated and thus the most vulnerable group. To effectively combat this rising threat, it is crucial to understand the tactics employed by fraudsters and leverage advanced technologies like machine learning to detect and prevent fraudulent activity with users’ cards and accounts.
Understanding the Fraud Tactics
Since modern IT infrastructures are well protected on the network and peripheral levels, massive infrastructure breaches require substantial resources on the fraudsters’ part. This makes large-scale infrastructure attacks economically unviable. On the other hand, the number of digital users is growing exponentially.
According to the latest research by DataReportal, up to 97.6% of the world’s population in 2023 owned at least one digital device with web access. Most of this online audience is not technologically sophisticated enough to be vigilant about the social engineering dangers. Which makes them much more lucrative targets for fraudsters.
Tactics employed by fraudsters include – counterfeit credit cards (in developing countries mostly), identity theft, account takeover, skimming, invoice fraud, card-not-present (CNP) fraud, and phishing attacks. They are usually used in combinations when executing a multi-stage attack. For example, a phishing email campaign might be executed to obtain the personal information of the user (things like ID number, Social Security Number, and other unique pieces of information).
This information can later be used to impersonate the user when calling the bank’s call center and trying to obtain temporary access to the customer’s bank account. Once access is obtained, the fraudster can then take over the account, execute payments, change withdrawal limits, and other account settings undetected.
To timely detect schemes like these, a financial institution needs to closely monitor all customer activity in real time and detect any anomalies. Traditionally, it was done using rule-based systems. However, with the rapid growth of digital footprints and the speed at which social engineering schemes evolve, it becomes progressively more and more difficult for humans to manually adapt rule-based configurations to address these challenges. And that’s where machine learning comes in.
The Limitations of Traditional Rule-Based Engines
While traditional rule-based engines like the StrongHold Fraud Prevention Platform have been widely used in fraud detection and prevention in the last 20 years, they have certain limitations. These systems rely on pre-defined rules and patterns, making them less effective in detecting complex and evolving fraud techniques. Human competence and the necessity to understand fraudsters and their thinking patterns often limit the effectiveness of rule-based systems.
Talent Availability
The first limiting factor, prevalent especially in the developing markets, is the availability of competent analysts to work on system configurations. Larger organizations can bridge this gap by hiring Western specialists with relevant expertise, but this is a costly solution, requiring large budgets. Smaller organizations are typically left with this problem on their own.
One of the useful side benefits of introducing machine learning to fraud detection and prevention processes is a dramatic reduction in human resource requirements. Machine learning is typically offered as Software as a Service solution, deployed in the cloud.
It requires a team led by a machine learning scientist, proficient in adapting known algorithms to the given problems and developing new methodologies and algorithms to meet unexpected complex challenges. The team would also include one or more data science engineers whose task would be to prepare training and validation datasets, perform exploratory data analysis and feature engineering stages of model training, and create data cards, reports, and instructions for DevOps teams for model testing and deployment.
When offered as Software as a Service, all these high-end specialists can be shared between multiple clients, thus the talent cost per organization decreases dramatically, while the efficiency of fraud prevention increases at the same time.
Speed of Adoption
Another potential limitation of traditional rule-based engines is their speed of adapting to the new fraud patterns. They are limited by the speed of human thinking and learning because any reconfiguration of rules is entirely up to full-time analysts who are working within your organization. Thus your analysts become a bottleneck in the process. It might not be that big of a problem for large organizations with fraud analytics departments consisting of dozens of people. But smaller organizations, again, are left with the problem on their own.
Machine learning significantly shifts the paradigm in fraud detection by offering a dynamic, automated approach to adapting to new fraud patterns, a process starkly different from the manual, time-intensive methods employed by traditional rule-based engines. The initial training of machine learning models, while dependent on the complexity of the model and the volume of data, can range from a few hours to several weeks.
This upfront investment is crucial for laying the foundation of a robust fraud detection system. Once the model is trained and operational, it begins to analyze transactions in real time, learning from new data as it becomes available. This adaptability is one of the key advantages of machine learning, as models can be designed to automatically update themselves or to alert analysts when a retraining cycle is necessary based on detected shifts in transaction patterns.
The ongoing re-training of machine learning models is an essential component of their effectiveness. This process can be significantly more efficient than the initial training phase, especially if incremental learning techniques are used, which allow the model to update itself using new data without needing to be retrained from scratch.
Depending on the specific algorithms and the infrastructure in place, re-training can take from a few minutes to several hours, allowing for frequent updates to the model’s understanding of fraud patterns. This contrasts sharply with the laborious process of manually reviewing and updating rule-based systems, which can be both time-consuming and less responsive to emerging fraud techniques.
Comparatively, the standard process of configuring and periodically reviewing custom rule sets in present rule-based systems is often slower and inherently less flexible. Each adjustment or addition of a new rule requires manual intervention, from the initial analysis of fraud trends to the implementation and testing of new rules. This process takes time, during which time new fraudulent transactions may slip through undetected. Machine learning models, with their ability to learn and adapt automatically, offer a scalable solution that can reduce the time and resources required to maintain an effective fraud detection system, making them a very attractive option.
Self-Learning Capability
Thirdly, the one thing rule-based systems lack completely is self-learning capabilities. The rules and scenarios that are configured in the system are static and can only be changed manually by the fraud analyst. Combine this with a typical talent availability problem, present across most markets worldwide, and human analytical limitations – and you have yourself a real challenge to overcome.
The lack of self-learning capabilities makes rule-based systems not only slow to adapt to any changes but also requires fraud analysts to know about relevant fraud schemes and techniques in advance, before making configuration changes. Which makes any rule-based system post-factum by default.
In contrast to that, machine learning models can self-learn and suggest possible patterns in data, without human supervision. These algorithms belong to a family of machine learning approaches called unsupervised and self-supervised learning.
Introducing Machine Learning: A Paradigm Shift in Fraud Detection
Machine learning represents a paradigm shift in fraud detection. Unlike rule-based systems, machine learning algorithms can learn and adapt from vast amounts of data, enabling them to detect previously unknown or sophisticated fraud attempts. By analyzing variables such as transaction amount, timestamp, location, and user behavior, machine learning models can accurately classify transactions as either fraudulent or legitimate.
Machine learning algorithms can be divided into different types, each suited for specific tasks in the fraud prevention context. Let’s look at the most common types of algorithms we have already worked with and tested on real cases.
Supervised Learning
Supervised learning algorithms learn from labeled training data and can make predictions based on this learned information. This approach is especially useful for identifying known fraud patterns and behaviors.
Using training data, where suspicious or fraudulent transactions have been marked by an operator, even a relatively simple machine learning model can capture the distinguishing patterns between legitimate and illegitimate user activity with a high degree of accuracy. We have successfully tested several types of machine learning algorithms for this task, including random forest classification, feed-forward multi-layer perceptrons, and decision trees, producing area under the curve values exceeding 98%.
This shows that, despite the considerable effort involved in producing labeled data, supervised learning approaches are practical and promising in terms of accurately recognizing subtle and complex patterns in user activity and can use them to classify suspicious behavior with a high degree of accuracy automatically, a task that would require massive manual work when using a purely rules-based methodology.
Unsupervised Learning
Unsupervised learning algorithms analyze unlabeled data to uncover patterns and anomalies. This technique is particularly valuable in detecting previously unknown or emerging fraud patterns.
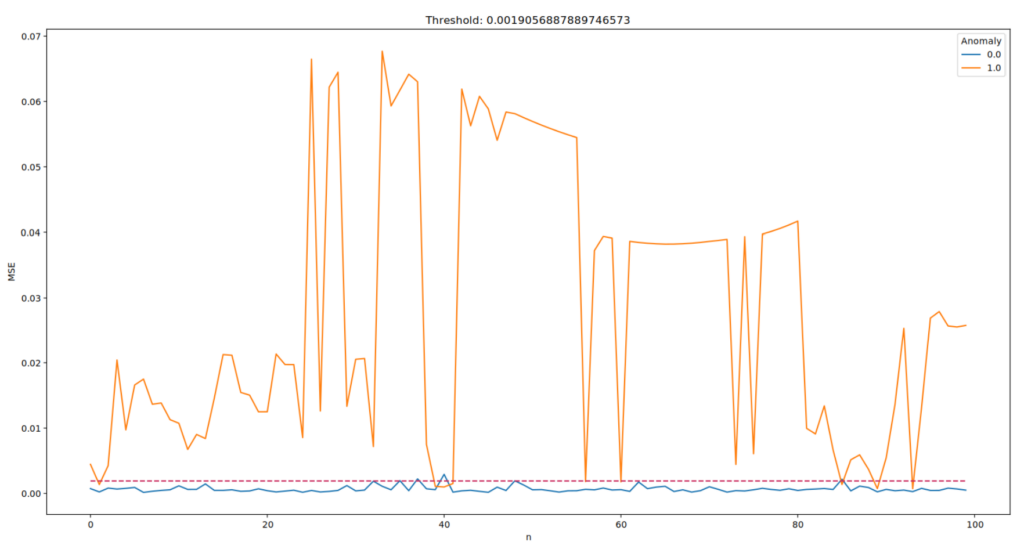
An unsupervised learning algorithm accurately detects and classifies anomalous patterns in the input data.
Unsupervised learning models also alleviate one of the common difficulties with providing training data, namely, the need to label the data into classes (anomalous vs. normal or otherwise). In the training stage, the model is provided with only non-anomalous data, which it uses to learn a baseline against which to compare new incoming data during inference
This process is general (i.e., not limited to a single type of anomaly) and can capture complex patterns in data, including non-obvious ones that would otherwise be particularly difficult to detect by human operators and/or efficiently describe using rules-based algorithms.
One of the most important and promising classes of unsupervised machine learning algorithms is the autoencoder, widely applicable for anomaly detection and classification. We have developed a working prototype of a new class of autoencoders, called Memory-Augmented Autoencoder (MAAE), which replaces the bottleneck of the regular autoencoder architecture with an addressable memory space for storing prototypical normal data shapes learned during the training, which are then used to guide the anomaly detection process during inference.
The MAAE architecture successfully mitigates a known problem with autoencoder-based models, where anomalous samples are sometimes reconstructed near to (i.e., hard to distinguish from) the normal samples, leading to reduced accuracy. The memory module of the MAAE network can be extended in various ways, including vector database-like querying capabilities, allowing the model to be steered toward anomaly detection for a specified subset of the learned samples.
Reinforcement Learning
Reinforcement learning algorithms learn through trial and error, continuously improving their performance based on feedback and rewards. This approach is well-suited for dynamic environments where fraud patterns may change over time.
Reinforcement learning is a dynamic machine learning-based approach to problem-solving based on learning how to make decisions with input through trials. Reinforcement learning solutions have many advantages over traditional methods when considering fraud detection and prevention.
In contrast to supervised learning, where pre-labeled data are needed to train the model, RL can adapt in real time to new patterns of fraud and keep refining the strategy of decisions. In contrast to conventional unsupervised methods, RL models can be “steered” based on the received feedback. This makes RL particularly suited to fraud detection, where strategies and tactics are constantly being changed.
One of the primary benefits of RL in fraud detection is its ability to optimize decision processes over time. In such a case, if the model under consideration gets “rewarded” with feedback in the form of rewards or penalties for the different actions it takes (like flagging a transaction as a fraud case), it can easily learn even subtle interrelations and anomalies typical for fraudulent behavior. Such a learning process means that highly nuanced models can be developed, which are robust enough to adapt to new strategies that fraudsters apply, without having to completely retrain them.
In banking and finance, RL can be applicable in the tracking of transactions as they occur and can be updated rapidly in the identification of new cases of fraudulent behaviors as compared to traditional systems. Apart from this, RL can be used to monitor the anomaly of the traffic across the network to identify possible threats in security breaches or insider threats in cybersecurity. These use cases exhibit how RL could be appropriately used for anti-fraud in different fields with high flexibility, providing a proactive and adaptive approach to fraud prevention.
The Role of Machine Learning in Fraud Detection
Machine learning models are pivotal in identifying and mitigating fraudulent activity. These models leverage historical data to train algorithms that can predict the likelihood of fraudulent activity. Machine learning professionals use different techniques to properly train the models, taking into account various parameters from the datasets. Hence, the more comprehensive datasets are available, the more precise and effective machine learning algorithms will be at screening customers’ activity.
The potential for using machine learning for fraud prevention needs is unlimited. However, there are several applications for machine learning algorithms that we have already found useful in practice. Let’s discuss them next.
Transaction Classification
Machine learning algorithms have already revolutionized the way financial institutions detect and prevent fraud, employing a range of techniques each suited to different aspects of transaction classification and fraud detection. Among the simpler, yet still effective models, logistic regression stands out for its efficiency in binary classification problems.
This type of model calculates the probability that a given transaction belongs to a certain class (fraudulent or legitimate) based on input variables. It’s particularly useful in scenarios where the relationship between the transaction features and the outcome is approximately linear, and the interpretability of the model’s decision-making process is crucial for regulatory compliance and manual review processes.
Random forests and support vector machines (SVMs) introduce more complexity and robustness into the fraud detection toolkit. Random forests, an ensemble learning method, operates by constructing multiple decision trees during the training phase and outputting the class that is the mode of the classes of the individual trees. This method is exceptionally good at handling large datasets with numerous variables, capable of capturing complex, non-linear relationships without overfitting.
SVMs, on the other hand, are effective in high-dimensional spaces, even when the number of dimensions exceeds the number of samples. They work by finding the hyperplane that best separates the classes in the feature space, making them particularly useful for fraud detection scenarios where fraudulent transactions are subtle and hard to distinguish from legitimate transactions.
Deep learning models, such as autoencoders and long short-term memory (LSTM) networks, offer advanced capabilities for detecting even more complex scenarios. Autoencoders, as used in our machine learning experiments, yield very good results at anomaly detection by learning a compressed representation of transactions and then reconstructing them; transactions that are reconstructed with significant error can be flagged as suspicious or constituting potential fraud cases.
LSTM networks, with their ability to remember information for long periods, are particularly suited for analyzing sequences of transactions to detect patterns indicative of fraudulent behavior over time. These deep learning approaches are capable of handling massive amounts of data and automatically learning feature representations, making them particularly effective for the dynamic and complex nature of fraud detection in financial transactions.
Cardholder and Device Profiling
By analyzing credit card usage patterns and transaction behaviors, machine learning models can distinguish between legitimate cardholders and fraudsters.
One of the most promising approaches to solving the owner-attacker distinction problem is using the so-called Siamese twin networks that consist of two identical networks that share their weights and are trained as a single model. In this architecture, a training sample is labeled positively if both sub-networks receive inputs from the same user, and negatively if each branch receives an input from a different user.
The network is trained to measure the difference between the outputs produced by the two sub-network “arms”; if this distance is large, it is an indication that the two inputs are produced by two different users, which can be filtered through a threshold for intrusion detection.
A Siamese network-based model is currently being developed by our team for mobile device real-time authentication and intrusion detection.
Outlier Detection
Machine learning algorithms can identify transactions that significantly deviate from typical credit card transactions using outlier detection techniques. This capability is crucial in detecting credit card fraud.
We have successfully tested several types of autoencoder-based outlier and anomaly detection models. An autoencoder is a type of unsupervised feed-forward artificial neural network architecture used primarily for dimensionality reduction, feature learning, and representation learning. It consists of two main components: an encoder and a decoder, which are symmetrically designed to work together.
The encoder transforms the input data into a lower-dimensional, highly compressed representation called the “code” or bottleneck, whereas the decoder reconstructs the original input data from this compressed representation. The autoencoder’s objective is to learn a compact representation of the input data while minimizing the difference between the input and the reconstructed output, which is measured by a loss function such as mean squared error.
When using autoencoders for anomaly detection, the network is typically trained on a dataset containing only normal instances. The assumption is that the autoencoder will learn to efficiently represent the structure and patterns inherent in the normal data while struggling to encode and decode anomalous instances accurately. Consequently, when the autoencoder is presented with an anomaly, the reconstruction error, as measured by the loss function, will be higher compared to normal data points.
To detect anomalies, a threshold is set on the reconstruction error, above which a data point is classified as an anomaly. This threshold can be chosen based on domain knowledge, statistical methods, or cross-validation techniques.
In our tests, the best autoencoder models reached over 95% accuracy in detecting anomalous activity in simulated scenarios. These figures could be further improved by using enhanced models, such as our MAAE neural network (see above).
Other Experiments
We have successfully developed and deployed a combined machine learning and heuristic approach-based natural language processing pipeline for automatically detecting and reconstructing word boundaries in input strings potentially containing typos, extraneous or omitted spaces, and other types of data corruption.
The pipeline is easy to extend with new heuristics (pattern-matching rules and transformations) and language feature classification models, supports multiple languages (and can be equally easily extended with more), and can perform near real-time on modest hardware resources.
Natural language processing is another area where machine learning-based approaches show great promise since NLP tasks typically require recognition of non-obvious patterns of data that would otherwise be hard to both detect and process.
Collaboration with Industry Participants
One of the big drawbacks of the now prevailing rule-based engines is that they operate in silos. Pretty much every financial institution today has a real-time or pseudo-real-time rule engine for screening customer activity in the digital space, operating as a standalone software in their infrastructures.
However, the most important piece in fraud analytics is data – that’s the vast ocean where all insights and patterns are hidden. The more data an organization has about user activity online, the more potential patterns and insights it can uncover. Without having access to the reliable and anonymized activity data of different users across all institutions within the industry, it will be difficult to uncover any new fraud patterns before your organization experiences them firsthand.
Unless you’re a licensed processor/service provider aggregating user activity data from multiple financial institutions, it has always been politically and regulatorily difficult to access user activity data across the market (even in an anonymized form). And having your rule-based systems siloed adds technological complexity to it.
Machine learning, when used in tandem with rule-based systems, can reduce at least the technological barrier for sharing data. An accessible REST API data feeder and unified data format ensure smooth data pooling, anonymization, and feeding into the machine learning algorithm, while predictive functions of the algorithm can also be accessed by multiple organizations via API.
This opens up new collaboration possibilities across all industry participants, where organizations can anonymously pool the data about user activity and benefit from insights and patterns within the vast pan-industry datasets.
Advantages of Implementing Machine Learning in Fraud Detection
Machine learning models offer substantial advantages over traditional fraud detection methods. Here are some of the key benefits of utilizing machine learning for fraud detection across digital channels:
Swift Detection
Machine learning models excel in real-time anomaly detection, swiftly identifying deviations from typical transaction patterns and user behaviors. This rapid response minimizes the risk of fraud and ensures more secure transactions.
Machine learning models stand at the forefront of enhancing fraud detection systems, offering a significant leap over traditional rule-based configurations. The primary advantage lies in their dynamic learning capability, which allows them to continuously adapt to new fraudulent tactics without the need for manual updates.
Unlike rule-based systems that rely on predefined criteria, machine learning models analyze patterns and correlations across vast datasets, enabling them to uncover subtle anomalies that might elude simpler detection methods. Our experience has demonstrated that these models can be trained to recognize fraudulent transactions with a high degree of accuracy, successfully detecting patterns that have not been previously encountered.
The efficiency of machine learning in fraud detection extends beyond just the breadth of detection capabilities. From our work, we’ve seen firsthand how parameter selection and tuning play a critical role in optimizing model performance. By carefully adjusting the models’ parameters and layer architecture, we’ve been able to reduce false positives without compromising the detection of genuine fraud attempts. This fine-tuning process is essential for maintaining user trust and ensuring a smooth transaction experience.
Moreover, the initial setup and ongoing maintenance of machine learning models, though resource-intensive in terms of computational power and data science expertise, ultimately reduce the average human resource requirements in the long run.
In contrast, rule-based systems demand continual manual oversight and updates to stay effective, a process that can be both time-consuming and prone to human error. Our findings indicate that, while the upfront investment in machine learning models for fraud detection can be significant, the efficiency gains, reduction in manual labor, and enhanced detection capabilities present a compelling case for their adoption.
Enhanced Accuracy
Traditional rule-based engines, especially if used in real-time preventive mode (being able to block user activity in real-time), are well known for their blindspots in detecting false negatives. A false negative is an event where the system has marked the user activity as genuine, while in reality, it was fraudulent. Most of the fraud losses are attributed to ineffective detection of false negatives.
In addition, if configured scenarios are overly restrictive, rule-based systems can also generate lots of false positives, which do not necessarily generate direct financial losses for the business, but impair customer experience and reduce the organization’s competitiveness over the long term.
Machine learning models, armed with substantial training data and insights, deliver higher accuracy and precision, reducing false positives, and false negatives, and the need for manual post-factum analysis.
A wide range of tools and metrics is available for measuring machine learning model classification performance, including true and false positives and negative counts, statistical error magnitudes, and richer metrics such as the ROC AUC curves, which provide insights into the classifier’s performance at varying threshold values. These figures provide more informative insights into the accuracy of the model, and allow for better adjustment with minimal downtime, compared to purely rule-based classification.
Unlike rule-based systems which are similar to conventional mechanisms composed of successive moving parts, machine learning models are in some relevant ways much closer to natural physical phenomena, in the sense that their behavior changes across a wide spectrum depending on parameters external to the system itself.
By adjusting the “temperature” of a model (in terms of its parameter set during both training and inference), it is possible to fine-tune the behavior of the model in ways that increase its efficiency and accuracy without needing to resort to changing its internal structure. This provides the data scientists with a flexible set of tools for optimizing and improving existing ML models beyond their initial performance ranges.
A common side effect of this flexibility is difficulty in precisely interpreting the model’s internal activity and the logic by which it arrives from input data to output predictions. However, a growing range of ML interpretability analysis tools exists and several of them have been successfully employed in our experiments, to provide detailed insights about the ways the models choose input data feature importance and transform these input data to arrive at the results.
In particular, it’s worth mentioning methods such as LIME (Local Interpretable Model-Agnostic Explanations), which approximates any black-box machine learning model with a simpler interpretable model to explain each prediction. LIME and several other related methodologies have been used by our team to analyze relatively complex ML models and gain useful insights into the internal logic of their behavior.
Efficiency with Large Datasets
When dealing with real-time rule-based configurations, the processing speed is crucial. Although we’re proud of our StrongHold Fraud Prevention Platform being one of the fastest rule-based engines on the market today, it comes at a cost. Our recent benchmarks have proven our system’s ability to handle high loads (up to 100 TPS in our benchmark) with a processing time of 18ms per request.
It’s enough to process more than 6 million user events per 24 hours in real-time. However, it does require significant hardware resources to maintain this benchmark – at least 64GB of RAM, with 10 vCPU cores @2.50GHz. Some of our clients are running installations at much higher volumes (up to 1,200TPS), requiring even more hardware to maintain the benchmark.
Machine learning algorithms help optimize this resource consumption. Machine learning algorithms efficiently handle large datasets, segregating genuine transactions from fraudulent ones in real time at a fraction of the resources required by a rule-based system. These models can process vast volumes of data within milliseconds, providing real-time insights that empower better decision-making.
For example, our transaction classification algorithm, running on a Python ML framework, uses batch processing to feed the model with a large number of events in a single packet, that are then processed simultaneously. The relatively high resource cost of the training process of these models is separate from and unrelated to the runtime classification activity, leading to a stable and predictable performance regime. The performance of the deployed models is easy to monitor over a wide range of metrics (accuracy, throughput, hardware resource utilization, and more).
Furthermore, both training and inference (classification) stages readily make use of GPU resources, with even modest numbers of GPU cores providing a performance increase that by far (up to several hundred times or more) exceeds that of an algorithm running purely on CPU. The ML framework supports both NVIDIA and AMD GPUs, automatically detects them, and adjusts the model accordingly.
Pairing Rule-Based Engines with Machine Learning Algorithms
To leverage the benefits of both rule-based engines and machine learning algorithms, organizations can pair these two approaches. Rule-based engines provide the necessary configuration framework, user access, a platform for integrations, back office functions (reports, etc.), and data visualizations. Machine learning services, however, provide unparalleled speed of processing big data volumes, can aggregate data from multiple organizations more easily, and require fewer resources to configure, train, and operate.
Therefore, we recommend using machine learning algorithms paired with rule-based engines for optimal performance of your fraud prevention processes. It is possible to build and train a whole portfolio of different machine learning models, each tailored to one specific task. For example, you can have different models for screening user login events, payment card transactions, user settings changes, user inquiries in the call center, etc.
Each model will be available for immediate, real-time use from the rule-based engine. Such configuration would allow you to have a framework of your analysis logic defined using easily configurable rules while conducting more nuanced analysis with the help of machine learning. Machine learning models, in this case, would require less maintenance time and would be capable of iteratively learning new patterns, according to changing activity data in real-time. This combination has the potential to enhance fraud detection capabilities and improve the overall effectiveness of your fraud prevention process.
The Future of Fraud Detection: Automated Machine Learning Services
As technology continues to advance, we see that the role of machine learning in fraud detection and prevention processes and programs will only continue growing. As fraud prevention platforms and machine learning algorithms advance, machine learning services will become more and more automated. These systems will be capable of analyzing vast amounts of data in real-time, detecting complex fraud patterns, and adapting to evolving threats with minimal human intervention. This will help reduce operational costs, while substantially improving fraud prevention efficiency.
Of course, having a fully automated, self-learning fraud detection system based on machine learning is probably further away in the future than we think. But the trend is moving toward that future and organizations that will not start experimenting with machine learning algorithms and their application to fraud analytics risk being left behind and suffering insurmountable losses in the future.
In conclusion, machine learning is revolutionizing the field of fraud detection and prevention in the payments business. With its ability to analyze large volumes of data, identify patterns, and adapt to new fraud techniques, machine learning offers substantial advantages over traditional rule-based systems. By leveraging machine learning algorithms, organizations can enhance the accuracy and efficiency of fraud detection, ensuring the security of digital transactions and protecting customers from fraudulent activities. As technology continues to evolve, the future of fraud prevention will increasingly rely on fully automated machine learning systems, paving the way for a safer and more secure digital payments landscape.
About The Author:



